Watchful Webinar Notes - Machine Teaching
Written on November 17th, 2021 by Daniel E
In a bid to stay up-to-date with the latest developments in the field of AI, I attended a webinar organised by Watchful, where they discussed Machine Teaching, the task of automating labelling of data for a machine learning model. In this webinar, a context is provided as well as challenges in the field and a new solution to address it all. This webinar provided me with a useful insight into the challenges in the world of data science.
Keywords
notes, data-science, machine-teaching, hand-labelling, explainability, interpretability
Watchfulio’s Webinar on Machine Teaching
In this article I refined my webinar notes into a piece of writing that I and others can revisit.
Machine Teaching is a new approach to building better machine learning applications, faster by bringing SME’s closer to the process by separating the “teaching” information from the algorithm. Subject-matter-expert labelling remains one of the biggest bottlenecks in delivering impactful machine learning applications. Problem owners often lack the necessary engineering and/or data science skills to implement their own model. Machine Teaching workflows enable SME’s to rapidly “teach” models through identifying the most valuable data on which to train on in a dynamic, interactive way.
In this webinar I joined Shayan Mohanty, CEO of Watchful, and Josh Singleton to discuss how machine teaching, a fundamentally transformative approach to human mediated machine intelligence, can be used to tackle the most valuable machine learning use cases. They gave a gentle introduction to the core concepts of Machine Teaching, as well as some examples of how Watchful employs this approach for developing machine learning models. Here’s what I learnt:
Summary
Watchful is a company that largely automates the process of creating labeled training data. The algorithm at the base of their platform is Machine Teaching (a term coined by Microsoft source needed), which is about making machines learn more like humans.
An AI System is made up of Code and Data, and depending on circumstances more work may be put in one of them but not the other. For a real-world AI system the aim is to keep a careful balance between the two.
This webinar focuses on the data side of things. Data consistency is key, but there is no set methodology on how one should iterate through data. With a machine teaching system in place, one can quickly deal with the following issues:
- how do you interpet/measure data quality
- how do you improve data quality meaningfully
- how do you identify how improvements in data contribute to improvements in the model.
- how do you deal with latent issues like bias and drift
Machine teaching system has 3 core pillars:
- Productivity (time to label, how quickly can I apply my knowledge on my data),
- Explainability (time to realisation, how quickly am I able to spot problems in my data),
- Agility (time to iteration (dealing with the issues listed before), how quickly can I react to change made in data).
 ^ Pairing a model with the right explainable technique is key, and can lead to powerful combinations.
^ Pairing a model with the right explainable technique is key, and can lead to powerful combinations.
Right now hand-labelling is a way to impart subject-matter-expertise into models, but ultimately it is has the fundamental flaw of making humans act like machines (taking data row-by-row, column-by-column). As mentioned previously the goal of machine teaching is to make machines act more like humans, by learning concepts through noise and applying them in ML workflows and on unseen data.
There are drawbacks to hand-labelling data. From the Seldon Webinar I learnt that the labelling of data is a point at which human biases can creep in, and once in the data, they can’t easily be remedied. Additionally:
-
Hand labels cannot be audited, and are not interpretable, explainable or reproducible: Being able to explain the data is critical to being able to find issues in it, as explained in Sambasivan, Nithya, et al’s ““Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI.” proceedings of the 2021 CHI Conference on Human Factors in Computing Systems. 2021.
-
Models that require lots of data or subject matter interpretation of the data are frequently cost prohibitive to build: Very often it is not possible to use a pre-existing labelling service or labels from other projects due to how wildly requirements vary from project to project. This means experts have to be brought in to do the hand-labelling. Over the lifetime of the learning model, there is a large amount of expert labelling needed, but the time and availability of the experts doing the labelling is scarce and expensive. This creates a bottleneck for ML pipelines.
-
Hand labelled data often does not capture the nuance of inter-annotator disagreement.
And it is due to these reasons that ML models frequently encounter issues downstream, ranging from performance issues all the way to use cases becoming completely untenable.
There are alternatives to hand labelling. With varying levels of human effort and supervision, heuristics can be used to weakly label large amounts of data for ML quickly. Alternatively, data can be synthetically generated so that it has the same statistical validity as “real” data. These alternatives have their own challenges and may not solve the problem anyways. This is why Watchful is producing a machine teaching platform.
Uncategorised notes
The question is not “Should I hand-label my data or should I label my data programatically?” but rather “Which parts of my data should I hand-label and which parts should I label programatically?”.
May be better to have more data with noisier data, rather than less perfectly labelled data.
There are many methods for ML explainability, the only constraint is access to scope of interpretation
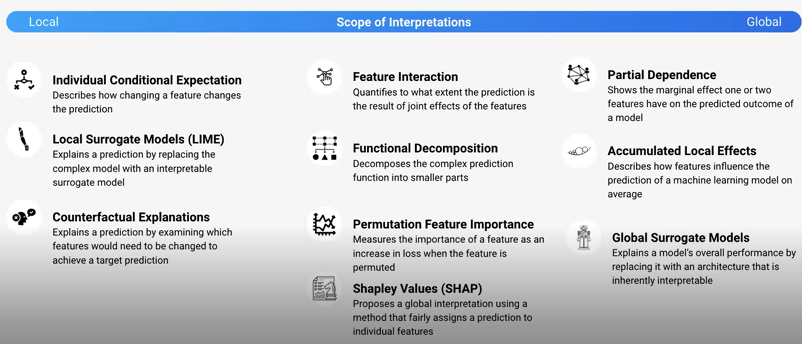
- In counterfactual explanations, where an event is the predicted outcome of an instance, the causes are a feature value of that instance.
- LIME (local surrogate models) also encountered in the Seldon Webinar, produces explanations at level of predictions. Predictions of deep learning models are difficult to explain, however, as they resemble a blackbox.
Handlabels can’t be reliably reproduced or explained because humans are fallible in silent and unpredictable ways.
Explainable labelling is crucial for a machine teaching system.
Balance is needed because time is key to keep ML models production ready. May choose slower inference sometimes. Weak supervision as ensembling method. Results are better than random. If you write a heuristic that says if an email says medical stuff it’s spam. You’ll get noise. Attackers can detect your heuristic and adapt. I can add noise and fuzziness. That is self explanatory but we still need to programmatically understand why and how we reached that. Active learning…… Machine teaching ultimately needs a bit of an ensembling
The best way of starting using the Watchful system is by hand-labelling some small amount of data to begin with, to get comfortable with it. Watchful learns some stats about classes, collinearities, and iterates fast. Creates a validation set. Produces a confusion matrix.
Some data can be programmatically labelled, some will have to be hand labeled. With Watchful you can introduce some level of supervision. But moving from classical (100% supervision) to a ML system with only some supervision is ideal, as you want to keep the transition smooth in a way.
Workflow in Watchful is a search function (data modality), suggestion, modelling/explanations – you go thru this loop constantly. If you can articulate a query/hypothesis/Py function then it’s a viable hinter. Can infer classes from handlabels.
Who should be implementing this? Not for everyone. Hand-labelling is a classic because it works for a lot of people. Consider machine teaching if subject matter expertise is necessary in the process of labelling; or if your data is private; or if your data is shifting frequently (like in spam/fraud classification– encode concepts as functions as opposed to hand labelling thousands of rows every five days.)
The datawork is hard, but noone wants to do it. You can get a model off the shelf and it’ll be fine.
Beyond labelling, data lifecycle parts that are hard are: data monitoring as a stats problem (fraud, I labelled all their tricks, 2% hitrate I put it into a model and it predicts 2%. A quarter later I get 20% prediction. What happened? I need to monitor…something. Data versioning for reproducibility)



