Cartpole DQL
Written on April 24th, 2020 by Daniel E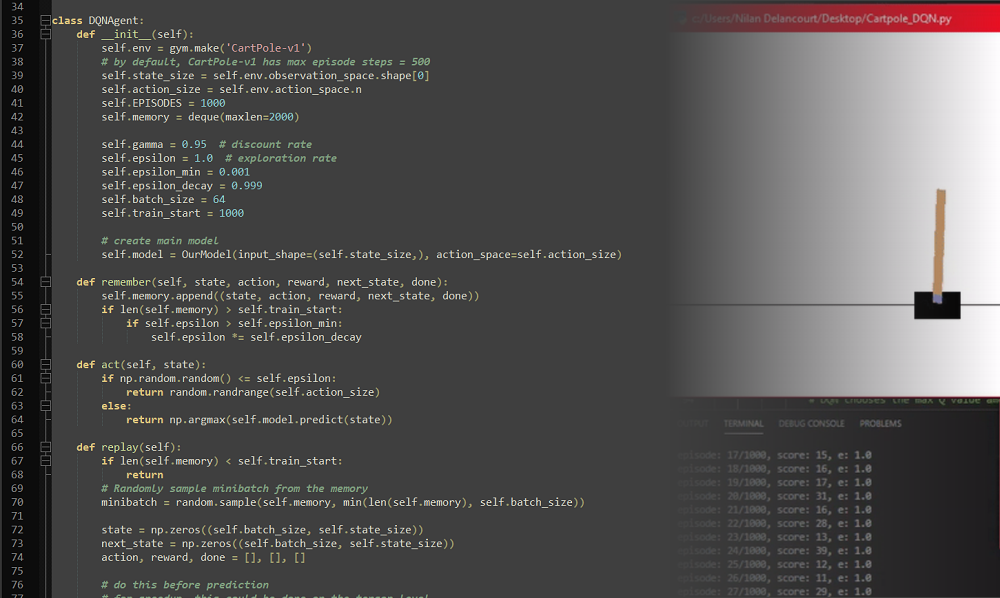
Introduction
Single agent reinforcement learning (RL) is machine learning domain where an arbitrary entity (known as an agent) interacts with an environment in timesteps. At each timestep ‘t’ the agent and the environment are in some state ‘s’. Every action causes the environment to yield a reward ‘r’ that may or may not be desirable. In its quest to maximise reward, an agent very often has trouble deciding whether it’s better to look for a more rewarding action (aka exploration), or to repeat an action that is known to yield some (desirable) reward (aka exploitation). The balance between the two is called a policy.
Q-learning is reinforcement learning with a Q-function. This function measures the expected return obtained from a state of environment by taking an action and following a set policy, and learns by updating its action-value functions.
Q-learning algorithm suffers from the curse-of-dimensionality problem as it requires discrete states to form the Q-table. The computational complexity of Q-learning increases exponentially with increasing dimension the state and action vector. Deep Q-learning solves this problem by approximating the Q-value function with an artificial neural network.
And is for that reason why for this project, DQN was chosen as the algorithm to solve the cartpole problem In order to solidify my understanding RL and its subsequent evolutions, they were put in action in a little simulation.
The problem of choice was cartpole. A pole starting upright is attached to a cart by a joint, and the aim is to prevent the pole from falling over as the cart moves along a frictionless track. The system is controlled by applying a force of +1 or -1 to the cart and a reward of +1 is provided for every timestep that the pole remains upright. The episode ends when the pole is more than 15 degrees from vertical, or the cart moves more than 2.4 units from the center. This problem is described in more detail in the original publication by Barto et al from 1983.
Keywords
Python3, numpy, OpenAI.gym, keras, Q-learning, neural-network, deep-Q-learning
Delivery
As mentioned previously RL problems are concerned with an environment, and an agent that observes and acts in accordance with those observations and a reward function to drive learning.
When an agent object is __init__iated, various relevant hyperparameters are set. These include the size of its memory, the gamma (a discount rate so the reward function yields a converging geometric-like series), and epsilon (the ratio between exploration and exploitation) values. The agent also contains the neural network model that takes the observation space (size 4) as input, and outputs an action (move left or move right)
Thanks to OpenAI gym, a collection of environments to develop and test RL algorithms, I was able to generate the environment in one line: self.env = gym.make('CartPole-v1'). The CartPole environment gives us the position of the cart, its velocity, the angle of the pole and the velocity at the tip of the pole as descriptors of the state.
My agent was defined to follow a decaying epsilon greedy policy (epsilon = 1, epsilon_decay = 0.999), meaning the agent starts with random actions (exploration) to fill up its memory, as one can only learn from experiences one has had. Over time the exploration rate (epsilon) is reduced gradually, and the agent begins to pick the best action it knows it can take (as you will see in the act method).

The remember method adresses a neural network’s inability to remember old experiences (they get overwritten with new experiences). For each of those experiences the Q value is updated, and we would like to keep a log of past experiences. This method does exactly that, storing state, action, reward, next_state variables from a single episode inside a deque.
In this algorithm I use experience replay. The replay method is responsible for training my neural network with batches of (random) experiences from memory. It tries to make a prediction on selected batch to get targets and targets_next. Then the Q value for action taken is updated with the reward[i], or with the reward[i] + self.gamma * (np.amax(target_next[i])).
While replay served as the method training the neural network and updating the Q function, the run method provides the training loop structure with episodes and the yielding of rewards, of course all the while saving every experience to memory. When the run method shows the agent performing well (balancing the pole for long enough, i.e. a high enough number of episodes), the model is automatically exported to file, and available for testing:
Final notes
This group project was done as part of my Computer Science degree in my Masters year, and was aimed at solidifying my understanding of reinforcement learning methods. In learning by doing, I applied one in a real case scenario. This proved to be a very effective learning strategy, one I carried with me since this project was completed. In working with a team, I also got to practice my interpersonal skills like collaboration and receptiveness to feedback.
This code can be found on my GitHub. This project was completed 24/04/2020.