Spam Detection with SVMs
Written on January 2nd , 2022 by Daniel E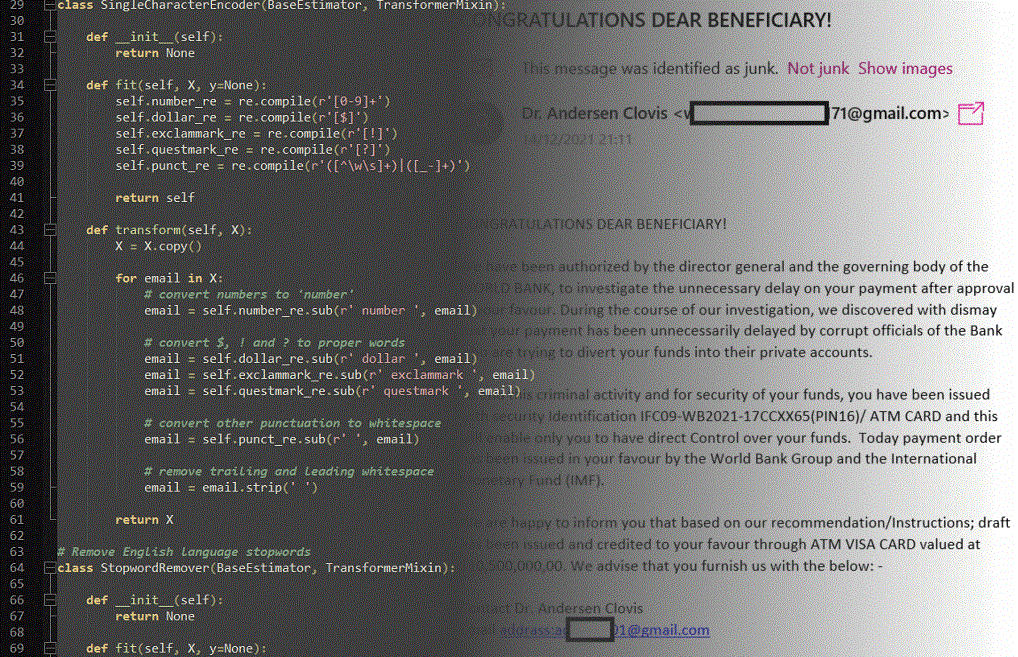
As part of the intensive AI skills bootcamp I’m taking part in, I’ve been working on an applied machine learning project to refresh and put into practice AI/ML skills in real world problems. This is the first of four projects I will be undertaking at the University of Huddersfield. The main focus of this project will be further building experience with the tasks a machine learning engineer would undertake in his day to day job, that is researching, developing, pipelineing and productionising ML products.
Project Introduction
The problem to be solved here is creating a real world spam filter that would classify clean and spam email with machine learning. The main evaluation metrics are accuracy, i.e. how many emails end up in the correct folders and recall, i.e. the proportion of spam email ending up in the spam folder. A high recall is an especially important metric as the goal of a real life spam filter is not allowing spam emails (potentially containing phishing, email bombs, other malware) reach the inbox folder. For this project I aim for very high values, 99.99% or better.
For this binary classification task there are multiple algorithm options. There are decision trees, k nearest neigbours, logistic regression, naive bayes and support vector machines, as well as neural networks and more. I chose to carry out the task with an SVM model. The main reason for this choice was my knowing that I would start with a small dataset, and that emails would have to be vectorised. This would mean a high dimensional feature space, potentially greater than the number of samples, a scenario perfect for SVMs.
The dataset is a combination of small, labelled datasets I found on the internet, the bulk of it coming from a part of enron. In the process of gathering data I sought to have a balanced dataset, with the share of spam emails only slightly lower than those ham. Upon concatenating different datasets, I ended up with an 11k large, 55-45 ham spam split, one I found to be the exact proportion of emails being sent every day worldwide [source needed] .
This project is in development.
The code can be found on my GitHub page.
Keywords
Python3, jupyter-notebook, scikitlearn, pandas, numpy, nltk, github, git, OOP, support-vector-machine, reproducibility, modularity, kernel-function, radial-basis, dimensionality-reduction, singular-value-decomposition, feature-selection, feature-reduction
The pipeline
With a Jupyter Notebook, I was able to quickly prototype a pipeline, before taking my best findings and actually translating it into a more modular, easier to read representation. With various components, switching them out and around to get better results. In terms of evaluation, the best I could find was 96% accuracy and 99% recall.
With simple pandas operations, I found very few empty values, whose rows I dropped altogether. I also made some sanity checks on the data before I began preprocessing.
In text data, there are a lot of natural language concepts that a computer/algorithm have trouble learning, leading to inaccurate inferences. For example, unless we stem verbs of their endings, an algorithm would see different verb conjugations or tenses differently, despite the verb conveying the same meaning every time. To aid the algorithm in learning what looks like legit email and what doesn’t, I sourced some regular expressions to quickly and efficiently preprocess textual email data. With them, I encoded email addresses and URLs to the words “emailaddr” and “webaddr”, numbers and punctuation to the words “number” and their respective punctuation symbol name, and stemmed words of endings using nltk English dictionary, and a few others.
As a model can only process numerical data, these emails needed converting once again, this time into vectors/matrices. I considered two feature extraction methods: CountVectorizer or Tfidfvectorizer. CountVectorizer simply counts the frequency of all words in an email. I decided not to use this one as it tends to make models bias in favour frequent words, potentially detrimental for my results. Instead, I chose tfidfvectorizer, which overcomes that problem by calculating individual word weightage. Using a ratio involving tf and idf, common words are penalised dataset wide, allowing the model to potentially pick up on rare but tell-tale signs certain emails might be spam (e.g. Winner!)
A support vector machine makes classifications by drawing a separator between the classes, transforming features with a kernel function to aid that process. The kernel function is only one of this learning algorithm’s hyperparameters, with C (regularisation parameter, defining how many misclassifications can be allowed) and gamma (deciding how close/similar two points have to be in order to be included in the same class) being the others.
I found it hard deciding what exact values would be best for these, so I ran a sklearn.model_selection.GridSearchCV on the parameter space to find the optimum. This is a central part of the research phase, finding the best model for the data in hand.
Experimenting with feature reduction
With the line of code features.shape I found that my feature space in my training set is of size (7902, 38867). That is sparse data, full of 0s that represent the words that do not occur in a certain email but are found in others. While a high dimensional feature space can be dealt with just fine by an SVM, it could also be the reason for my plateau in accuracy. Naturally, I thought it would be wise to reduce those features to a select few that are very efficient in holding information. As a result, I decided to branch out of main and experiment with some of dimensionality reduction methods.
Scikitlearn has a wide variety of ready to use, off-the-shelf feature reduction methods. So far, I tried linear discriminant analysis, principal component analysis and truncated singular value decomposition. The first two require sparse data to first be converted into dense matrices, a process that turned out to be very expensive computationally, this step alone taking 10-30 minutes on a 4 Core 4GHZ Intel i3 10th Gen 16GB RAM 4GB GPU machine.
The following are the results I got after reducing my features, with new steps following the vectorisation of the emails.
After first scaling my features with sklearn.preprocessing.MaxAbsScaler, quite surprisingly, my SVM with LDA reduced features yielded 99% train accuracy and 46% test accuracy.
Computationally, TruncatedSVD ended up being a much more manageable choice, which allowed me to experiment with some of its parameters.
| no of components | train & test accuracy |
|---|---|
| n=2 components | 81% train accuracy and 54% test accuracy |
| n=10/15/20 components | 94% train acc and 80% test acc |
| n=50/100/1000 components | 95% train acc and 78% test acc |
This showed me reducing to 10-20 features yields the best results. Upon rearranging the dimensionality reduction and scaling steps, scaling after reducing features, I found my SVM classifies unseen data with 90% accuracy, a sizeable increase. I believe this combination meant less information loss.
With fewer features, GridSearchCV finds linear as being the optimal kernel for my SVM, likely because the data has become linearly separable. This contributes to a much quicker training time compared with before, along with obviously having much less data to fit.
This is promising regardless, and more research has to be done in the jupyter notebook.
Final notes
- More pydocs required. Even when you think there’s enough, there isn’t. MUST. DOCUMENT. MORE.
- As long as my metrics aren’t hitting my desired targets, I have to spend time in the jupyter notebook investigating causes and solutions to my sub-optimal results.
- Reproducibility is a challenge, with randomisation coming from lots of directions, sometimes even from outside the environment (potentially GPU floating-point discrepancy?). Regardless, I am educating myself on causes and solutions, this recent paper being just one of the sources I’m using
- Custom kernel on the way: in a bid to further optimise my model, and develop a deeper understanding of kernel functions, I aim to develop a custom kernel for this SVM. Part 2 article incoming too.
This project is in development.
The code can be found on my GitHub page.